Data Lake
What is a Data Lake
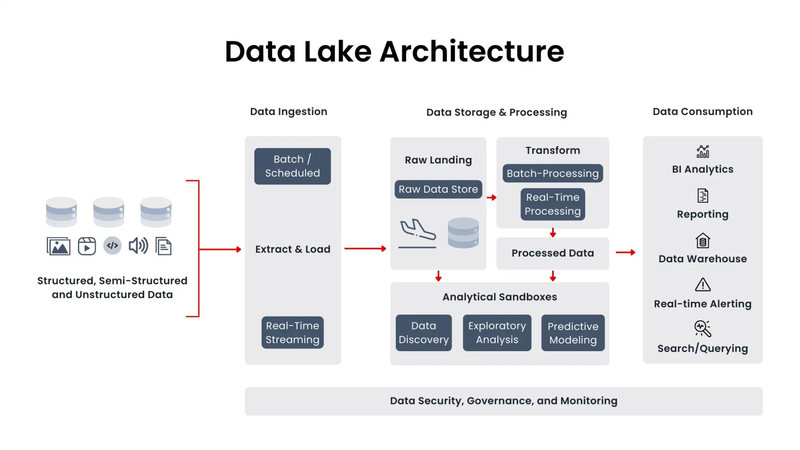
A data lake is a centralized repository that allows you to ingest, store, process and analyze any types (structured, semi-structured, and unstructured) or volume of data.
You can store any type of data like relational data from business applications, social data, real-time data, text, media, and more.
You don't need to convert it to a predefined schema before storing it.
Why use a Data Lake
- Cost-effective storage: Store vast amounts of data at a low cost.
- Scalability: Scale to store petabytes of data.
- Flexibility: You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
- Data sharing and collaboration: Store data from different sources and different formats. This means any department (data scientists, business analysts, data developers) can access the data they need to discover new insights.
Challenges of Data Lakes
- Data Quality: Without proper data quality controls, data lakes can become data swamps, where poor data quality makes it difficult to extract meaningful insights.
- Data Governance: Managing and enforcing data governance policies is important to ensure data quality, security, and compliance.
- Performance: Querying and processing large volumes of unstructured data can be slower compared to structured data in traditional databases.